Podrias hacer un ejemplo en/para android studio.
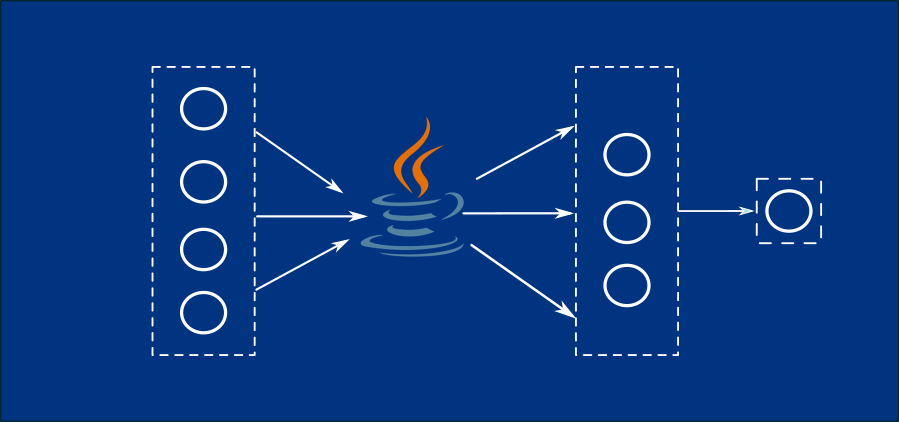
Tienes otros ejemplos, estoy tratando de entender redes neuronales, por que quiero hacer una que compare imágenes pero en android stuido, con java
En el sitio actual se están utilizando cookies para mejorar su experiencia. Si desea conocer un poco más sobre el tema, puede leer las políticas de privacidad y las políticas de cookies actualizadas.

 "juanmdh"
"juanmdh"